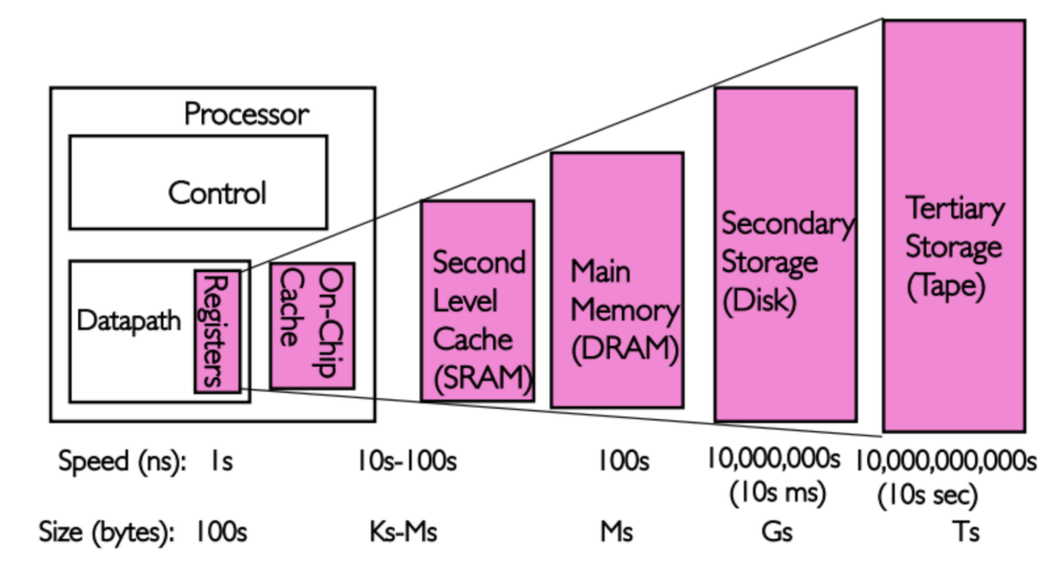
CPU Cache 是指 L1L2 和 L3 缓存,他们是用来缩短 CPU 访问内存时间的部件, 他们容量小于内存大于寄存器文件,但访问速度几乎接近处理器处理的速度.
缓存之所以能提高性能是利用局部原理提高内存的访问速度, 局部性原理是指程序具有访问局部区里的数据和代码的趋势, 通过在 CPU Cache 里存放经常访问的数据, 大部分需要在内存中执行的操作都能在 CPU Cache 中快速的完成.
局部性原理分为:
时间: 同一个 data 会在将来被访问
空间: 同一个 data 附近的区域会被访问
这是通用的 CPU cache 架构
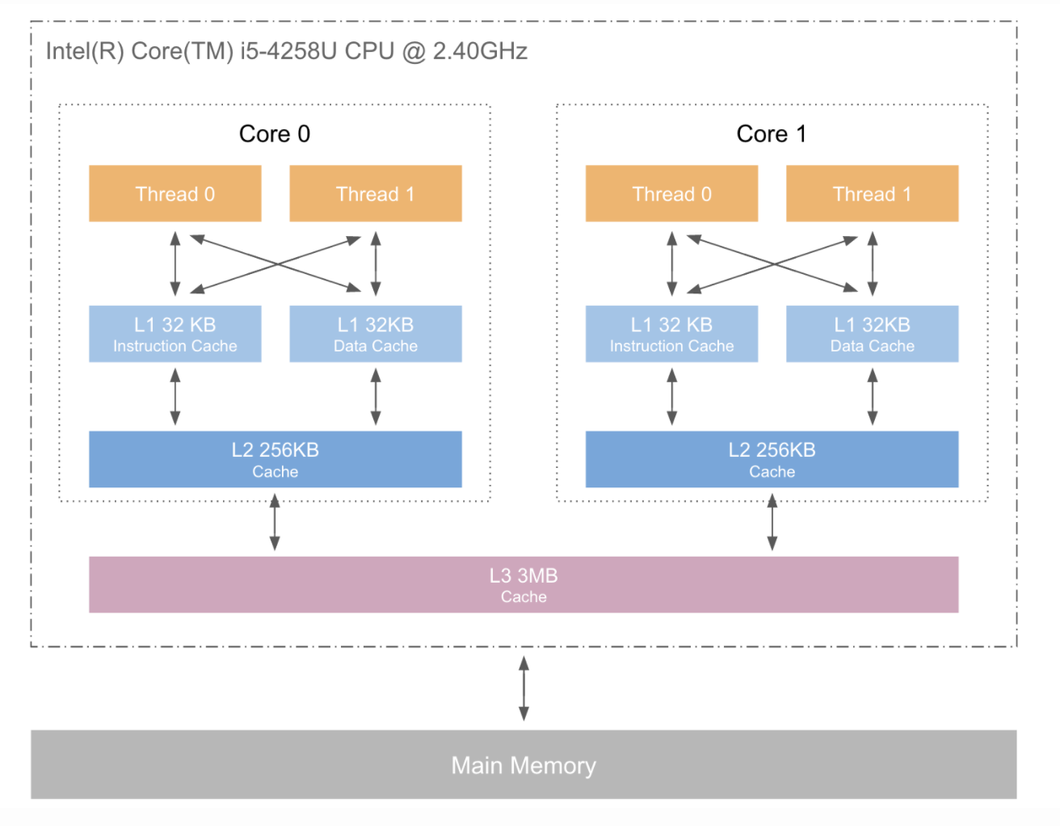
L1 和 L2 是在每个 CPU 核上, L3 则是多核之间共享

这里可以看出 L1 速度大概是 L2 的 2 倍以上, 而内存 L2L3 的容量是 L1 的好几倍, 如果我们能让访问内存尽量都落在 L1 上速度就会有显著的提升.
Cache Line: 在缓存内存到 CPU cache 上的时候不是一个 byte 一个 byte 的拷贝和管理而是一个 Cache Line 的大小通常是一个 word 字的大小. Cache Line 是内存上相邻的内存块. 不同的 Cache Line 的大小可能不一样.
sysctl -a | grep cacheline // 查看 L1 cache line 的大小
hw.cachelinesize: 64
Shell
L1 的 cache 大小, L1 的缓存
$ sysctl hw.l1dcachesize // 查看 L1 的 cache sise 大小
hw.l1icachesize: 32768
$ sysctl -a | grep cachesize // 查看 cpu l1, l2, l3 的缓存大小
hw.cachesize: 17179869184 32768 524288 8388608 0 0 0 0 0 0
hw.l1dcachesize: 49152
hw.l1icachesize: 32768
hw.l2cachesize: 524288
hw.l3cachesize: 8388608
Shell
所以如果需要处理的数据和 L1 的缓存大小接近可以类似几乎所有数据都会被缓存在 L1 中, 而当数据远大于 L1 缓存大小的时候,一些访问数据的顺序和方式会明显的影响程序的性能.
比较常见的一个二维数组矩阵处理优化, 把二维矩阵拆分为一个个小矩阵单独做处理, 这个小矩阵的大小远小于 L1 的 Cache Size
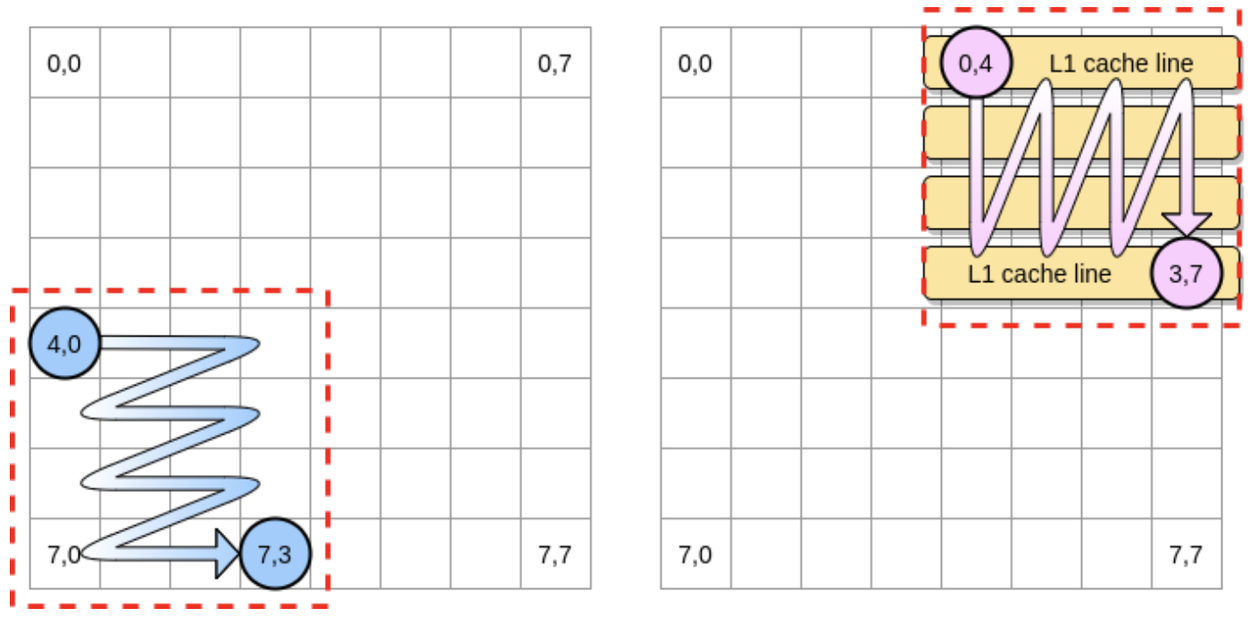
False cache line sharing
因为每个 CPU 都有自己的 L1 L2 cache , 所以变量可能同时被 cache line 缓存在 CPU1 和 CPU2 的 L1 上, 当数据发生修改时, 两个缓存之间就会产生一致性问题. 通常,处理器都实现了 Cache 一致性 (Cache Coherence)协议。
例如 MESI 协议这个协议里面 Cache Line 对应4中状态
modified 状态的 cache line 是由于相应的 CPU 进行了写操作,同时也表示该数据不会存在于其他 CPU 的 cache 中。也就说明这个最新的数据目前是被执行写操作的 CPU cache line 独占的。因为如此当前 cache 需要对该数据负责,比如将该数据传递给其他 CPU cache ,或者是将该数据写回到 memory 中。而这些操作都需要在 reuse cache line (置换)之前完成。
exclusive 状态和 modified 状态类似,区别是 CPU 还没有修改 cache line 中的数据。在 exclusive 状态下 CPU 可以不通知其他 CPU 而直接 cache line 进行操作。也就是说 exclusive 状态是该 CPU 对这个数据的独占。此时由于 memory 中和 cache line 中的数据都是最新的,所以不需要对 exclusive 状态的 cache line 执行写回 memory 的操作就可以直接 reuse。
shared 状态的 cache line ,其数据可能在一个或者是多个 CPU cache 中,此时 CPU 不能直接修改 cache line 中的数据,而是需要先通知其他 CPU cache 。和 exclusive 一样, shared 状态的 cache line 对应的 memory 中的数据也是最新的,因此也可以直接 reuse cache line。
invalid 状态时 cache line 是空的。当新的数据要进入 cache 的时候优先选择 invalid 的 cache line ,之所以如此是因为如果选中其他状态的 cache line 会涉及到 cache line 中数据的置换 , 而之后如果这个被替换的数据被访问到会造成 cache miss ,这样造成很大的开销。
这个网站可以直观的模拟 MESI 协议的状态图
当我们有两个处理器 A 和 B, 都在各自本地 Cache Line 里有同一个变量的拷贝时,此时该 Cache Line 处于 Shared 状态。当处理器 A 在本地修改了变量,除去把本地变量所属的 Cache Line 置为 Modified 状态以外,还必须在另一个处理器 B 读同一个变量前,对该变量所在的 B 处理器本地 Cache Line 发起 Invaidate 操作,标记 B 处理器的那条 Cache Line 为 Invalidate 状态。若处理器 B 在对变量做读写操作时,如果遇到这个标记为 Invalidate 的状态的 Cache Line,即会引发 Cache Miss,从而将内存中的数据拷贝到 Cache Line 里,然后处理器 B 再对此 Cache Line 对变量做读写操作 这样就会产生极大的性能问题. 这种情况被称为伪共享 False cache line sharing 本质上是不同的变量因为在一个 Cache Line 里面产生了共享的情况.
对于这种情况一般使用 memory padding 的方式进行优化,就是在冲突的变量之间放一些不会用到的空间进行占位
以 Golang 代码为例
type A struct {
x uint64
_ [56]byte
y uint64
_ [56]byte
}
Go
有 Padding 会比没有 Padding 的速度快一倍左右
参考资料:
 Foreversmart
Foreversmart