最近在线上查日志的时候发现有一个服务器上的日志时间延迟非常大,有的延迟几分钟有的延迟了好几天
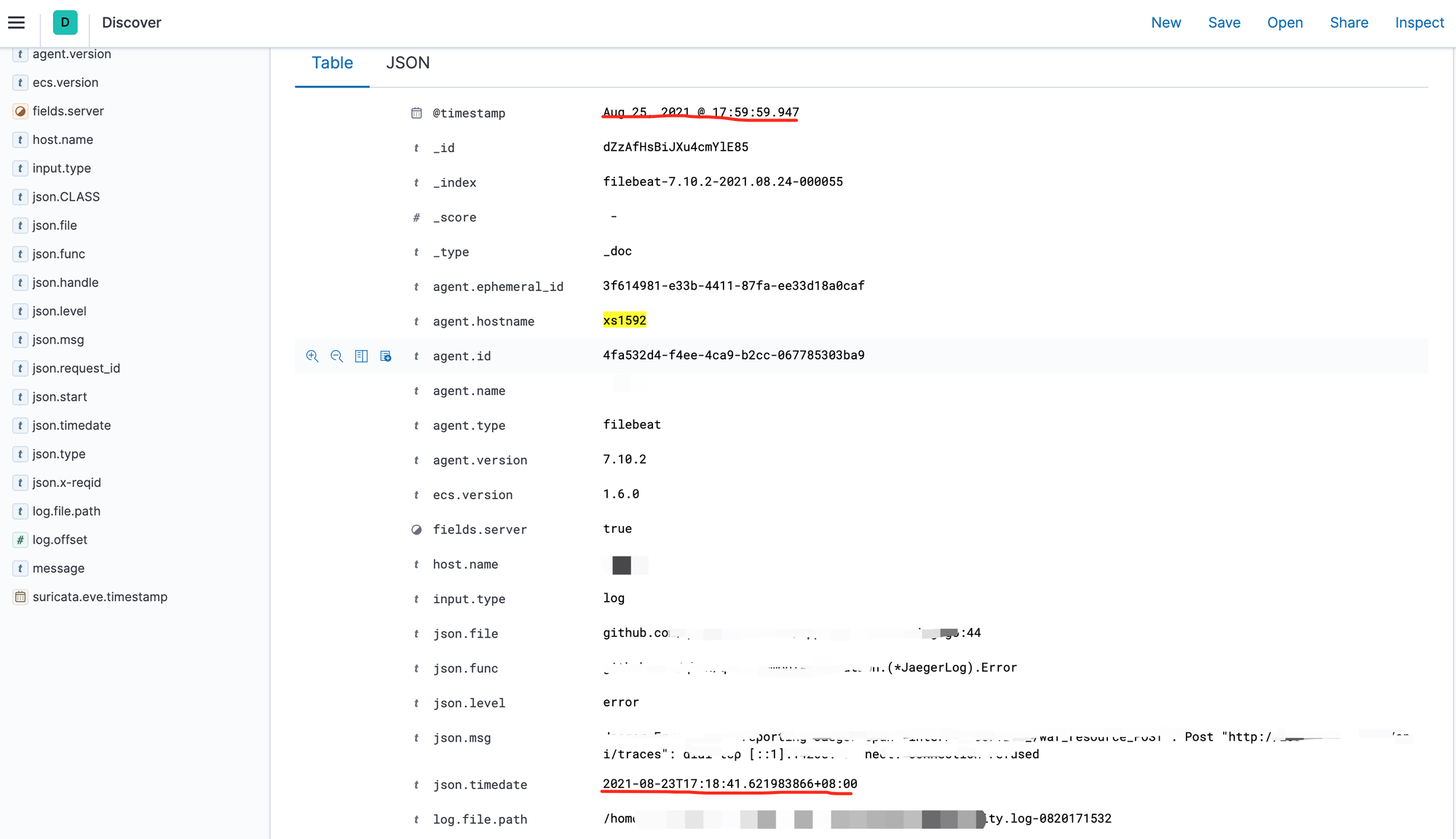
线上各个服务的日志是通过 filebeat 采集到 Elasticsearch 上的,多个服务部署的实例里面只有特定一台机器上的日志有延迟,所以排除了是 Elasticsearch 本身的问题导致的日志延迟。所以推断这个节点上的日志延迟,是由于 filebeat 的原因导致的。
我们通常通过 filebeat -c <config_file> -e 运行filebeat 这样就可以很方便的从控制台获取相应的日志输出。但是在上诉出现问题的机器上的 filebeat 日志中没有发现相关的错误信息,反而一切运行的都很正常。查看节点的 CPU,IO ,Mem , Network 情况都没有出现异常的情况,那究竟是什么原因导致我们的日志延迟的呢
在进行问题分析前我们需要看下 Elasticsearch 部署的通用架构图:
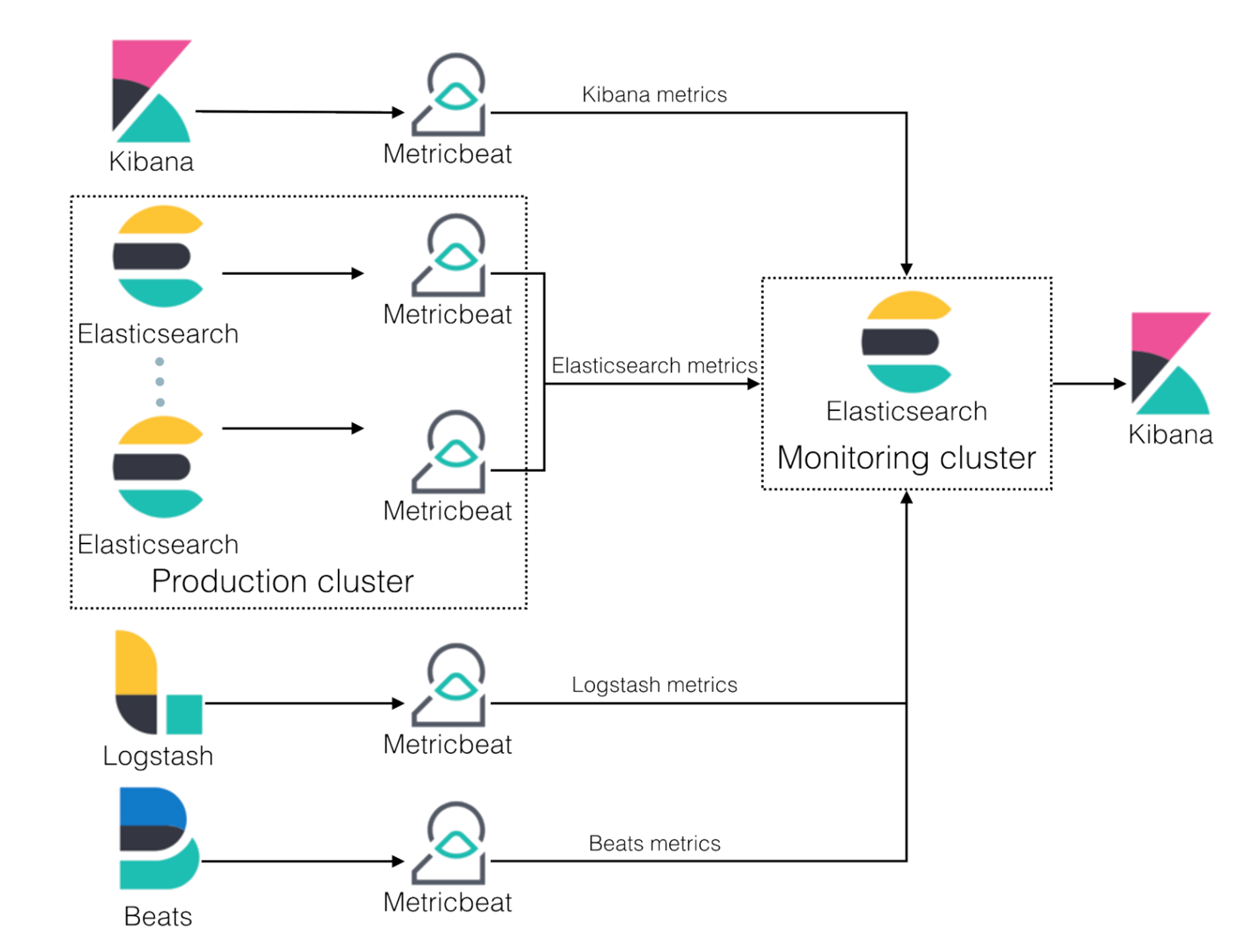
filebeat 会收集节点上各个服务产生的 log 然后发送给 Production Cluster 上的 Elasticsearch 集群,在这个过程中我们可以部署 Metricbeat 将 Filebeat,Elasticsearch,Kibana 的 metric 数据收集起来发送给 独立的 Monitoring cluster 上的 Elasticsearch 集群。
主要性能参数
workers 表示有多少个线程去写数据到 Elasticsearch
bulk_max_size 就是 batch size 表示一个 batch 中有多少个 document 被发送给 Elasticsearch
最优值分析:
由于数据类型,硬件,网络环境,Es shards 数量的不同,batch size 的最佳大小可能会非常不同。那怎么测量 batch size 的合理大小呢,我们可以选择一个从默认值 50 开始,不停的翻倍这个数值,直到我们在监控中看到的 Event Rate 和 Throughput 数据没有新的提高时前一个值就是我们期望比较合理的数值。
比如我们对比 50:100 如果 100 的性能明显由于50 就继续选取100:200 进行比较,否则50 就是我们认为比较理想的值。
同理我们也可以通过这方式找到理想的 worker 数量
但是当我们结合这两个参数进行观察的时候,是否在单一控制变量法中获取到的两个值是最优的情况呢?其实不是,我们在结合这两个参数进行参数选择的时候我们需要和上面的方式一样,指数倍增的方式去组合这两个值所有的可能来寻找最优的情况。
经过上面的分析,我们尝试手动调节下出问题的节点上的 filebeat 配置文件改为
output.elasticsearch:
bulk_max_size: 1000
workers: 2
Shell
然后重启 filebeat,过一段时间观察发现有问题的节点的日志逐渐恢复正常。
小结:应该是由于默认的 workers 1 和 bulk_max_size 50 导致 Filebeat 的 吞吐性能有限,然后这个节点上产生的日志数量可能比较多,导致了日志积压从而日志的延迟越来越大。
高级配置
Queue 相关的配置
queue.mem.events = 2 * workers * batch size
queue.mem.flush.min_events = batch size
Shell
通过这个配置我们可以提高吞吐量,但是会消耗额外的内存和牺牲一点实时性
数据压缩
默认情况下 filebeat 不会压缩数据进行传输,当我们发现网络带宽成为我们吞吐的一个瓶颈的时候我们可以通过设置适合的压缩率,来提高吞吐。但是高压缩率意味着我们会需要消耗额外的CPU 资源
output.elasticsearch:
bulk_max_size: 1600
worker: 16
compression_level: 9 // 设置最高的数据压缩率
Shell
结论
在上面的调优过程中我们主要关注的监控项是 Event Rate 和 Throughput 来分析系统的吞吐,在实际分析的过程我们还需要关注其它的一些系统指标。
比如我们发现 CPU,内存,网络,磁盘 IO 紧张的时候我们可以通过简单扩展的方式,增加系统能使用的资源。
或者发现有的请求被目标 Elasticsearch server 拒绝,然后 filebeat 会重试这些请求,大量的重试也会降低系统的性能。
我们需要全面的进行指标分析,否则就可能会判断错系统性能低下的真正原因。
 Foreversmart
Foreversmart