我们来看下面这样的一段代码
var arr []int64
func IncrArrItem(s, e int) {
for i := 0; i < 200000000; i++ {
arr[s]++
arr[e]++
}
}
Shell
这个代码的作用是对的数组中的第 s 和 e 位置的元素进行 N 次自增操作
我们写一个简单粗暴的检查性能的代码:
func calcTime(i int) {
start := time.Now()
wg := sync.WaitGroup{}
wg.Add(1)
go func() {
IncrArrItem(i, i+1)
wg.Done()
}()
wg.Add(1)
go func() {
IncrArrItem(i, i+1)
wg.Done()
}()
wg.Wait()
end := time.Now()
fmt.Println(i, i+1, end.Sub(start).Milliseconds())
}
Shell
这个代码会开启两个协程并发执行 IncrArrItem 操作并统计结束的时间
运行这个代码会出现和大家完全想象不一样的结果:
0 2 576
1 3 560
2 4 558
3 5 564
4 6 564
5 7 558
6 8 557
7 9 9689
8 10 550
9 11 551
10 12 553
11 13 549
12 14 553
13 15 563
14 16 609
15 17 9525
16 18 557
17 19 556
18 20 560
19 21 555
20 22 560
21 23 557
22 24 554
23 25 9681
24 26 549
25 27 550
26 28 556
27 29 548
Shell
上面的结果第一个是 s 第二个 e 第三个是执行的时间单位 ms
可以看到这些类似的操作执行的时间并不相同在
7 9 9689, 15 17 9525, 23 25 9681 都是其它执行时间的 10 倍
我们可以扩大这个范围发现这个规律仍然有效, 每 8 个出现一次
而 8 个int64 正好是一个 cpu cache line 的大小. 为了验证我们的猜想是不是正确我们可以将 int64 的 arr 数组改成 int32 的数组发现果然
0 2 569
1 3 566
2 4 560
3 5 559
4 6 558
5 7 567
6 8 563
7 9 562
8 10 560
9 11 561
10 12 559
11 13 558
12 14 563
13 15 564
14 16 560
15 17 9805
16 18 555
17 19 551
18 20 553
19 21 549
20 22 561
21 23 552
22 24 565
Shell
出现10倍性能差的规律变成了每16个出现一次. 那现在显然可以初步得出结论是相邻两个 cache line 并发的时候会有性能问题, 因为正好在第 8 个时候跨了 cache line. 为了校验是否是 cache line 之间产生的问题, 我们可以修改下我们的测试代码
func calcTime(i int) {
start := time.Now()
wg := sync.WaitGroup{}
wg.Add(1)
go func() {
IncrArrItem(i, i+2)
wg.Done()
}()
wg.Add(1)
go func() {
IncrArrItem(i, i+3)
wg.Done()
}()
wg.Wait()
end := time.Now()
fmt.Println(i, end.Sub(start).Milliseconds())
}
Shell
可以看到输出结果
0 553
1 536
2 541
3 541
4 541
5 867
6 7889
7 9110
8 532
9 530
10 529
11 527
12 530
13 881
14 9191
15 9396
16 540
17 536
18 541
19 540
20 545
Shell
当第一个协程里面的 s = 6 e =8 第二个协程里面的 s = 6 e =9 性能20倍
当第一个协程里面的 s = 7 e =9 第二个协程里面的 s = 7 e =10 性能20倍
这个规律也是按8循环的,我们还可以修改 s ,e 为 一个 cache line 里面其它的可能都出现了极差的性能. 我们还需改下代码这里不就具体展示代码 把 e 改为 i+9 或 i+1+n*8 这里也出现了相同的问题,说明不是相邻 cache line 导致的问题而是 跨 cache line 导致的问题. 这个问题
为了进一步证明猜想通过几种控制变量的办法来修改:
在第一个 go() 后面加一个 wg.Wait(), 这样程序就变成了线性操作.发现此时没有出现周期性的性能变差.说明前面出现的现象可能和并发有关
修改代码每个 IncrArrItem 的操作虽然有跨 cache line 的问题, 但是这两个并发的 IncrArrItem 操作的是不同的 cache line
IncrArrItem(i, i+8) // first
IncrArrItem(i, i+8) // second
Go
稳定在 9669 ms
IncrArrItem(i, i+8) // first
IncrArrItem(i+8, i+8) // second
Go
稳定在 842 ms
我们通过 go prrof 工具分析 cpu 执行时间
48 . . func IncrArrItem(s, e int) {
49 . . k := int64(s)
50 13.05s 13.32s for i := 0; i < 200000000; i++ {
51 1.05s 2.90s arr[s]++
52 29.83s 31.62s arr[e]++
Go
发现大部分的性能消耗都是花在第二个操作上
我们修改下代码把循环里面同时修改多个 cache line 的内容 k = s+8 y = k+8 x = y+8 u=x+8 v = u + 8
51 13.89s 14.25s for i := 0; i < 200000000; i++ {
52 320ms 2.30s arr[s]++
53 19.90s 20.74s arr[k]++
54 9.05s 10.26s arr[y]++
Go
52 10.89s 10.97s for i := 0; i < 200000000; i++ {
53 190ms 1.15s arr[s]++
54 20.30s 21.04s arr[k]++
55 1.73s 2.55s arr[y]++
56 11.07s 12.01s arr[x]++
57 . . }
Go
53 7.61s 7.70s for i := 0; i < 200000000; i++ {
54 640ms 1.54s arr[s]++
55 16.57s 17.30s arr[k]++
56 1.74s 2.53s arr[y]++
57 14.16s 14.67s arr[x]++
58 2.96s 3.90s arr[u]++
59 . . }
Go
54 4.61s 4.72s for i := 0; i < 200000000; i++ {
55 320ms 1.09s arr[s]++
56 15.69s 16.21s arr[k]++
57 1.20s 1.86s arr[y]++
58 3.78s 4.35s arr[x]++
59 16.65s 17.29s arr[u]++
60 1.83s 2.21s arr[v]++
61 . . }
Go
k y x u v 依次加1
54 8.34s 8.45s for i := 0; i < 200000000; i++ {
55 630ms 1.65s arr[s]++
56 22.07s 22.53s arr[k]++
57 2.51s 2.83s arr[y]++
58 1.61s 1.93s arr[x]++
59 7.23s 7.94s arr[u]++
60 1.82s 2.34s arr[v]++
61 . . }
Go
可以看出虽然操作和冲突的变量增多但是总的时间几乎没什么变化,都在32s 左右
MESI 协议
我们先来看下 CPU cache 一致性协议 MESI
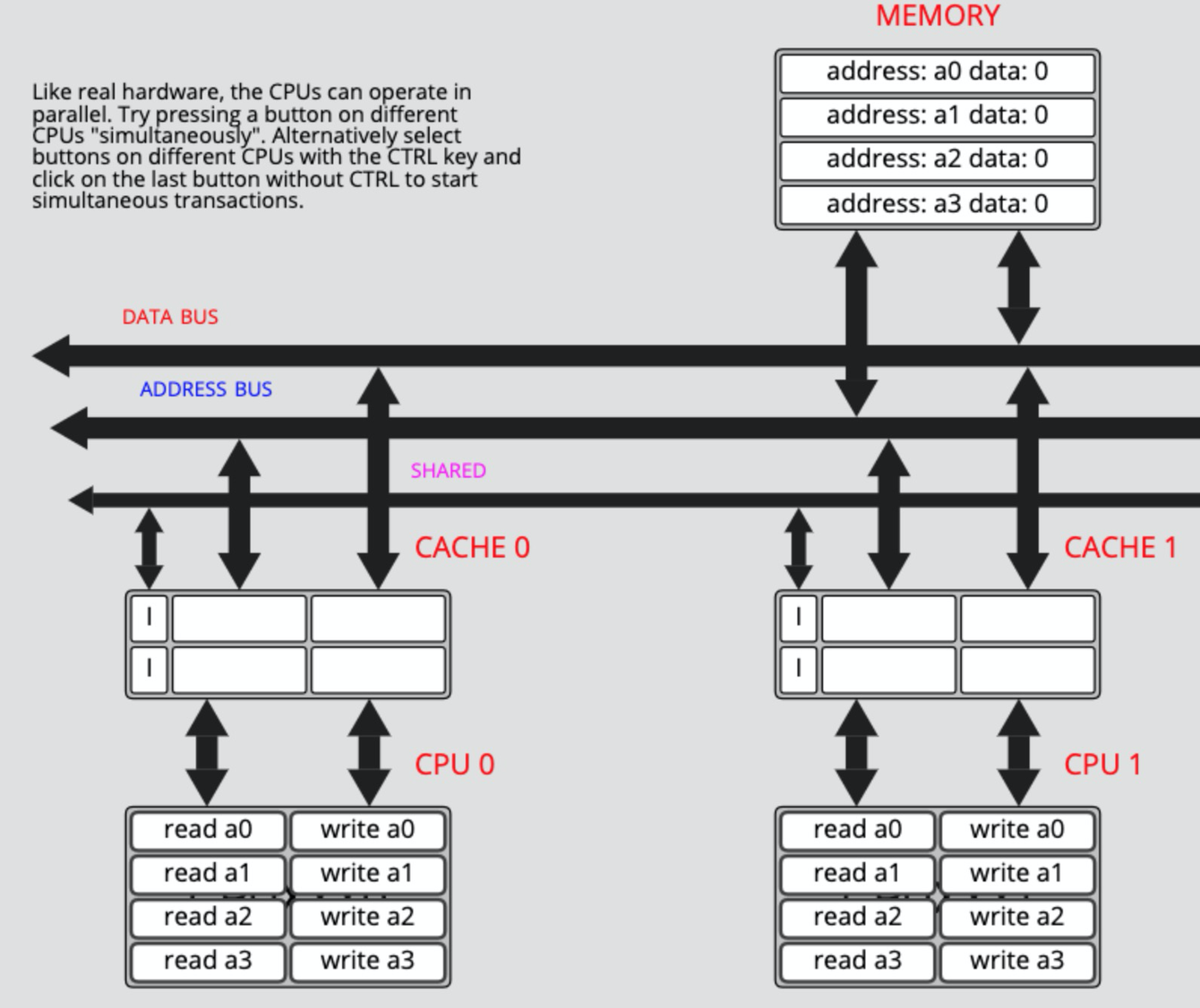
简单来说缓存的状态分为:
M : modified
cpu 对 cache line 进行了写操作,当前的数据是最新的独占有效,可以直接写 cache 不用回写内存和通知其它 cpu, 状态一直是 M
E : exclusive
和 M 状态类似,区别是此时 cpu 还没有对 cache line 进行写操作,Memory 中的数据和 Cache 中的数据一致,状态变为 M
S : shared
数据同时在多个 CPU 的 Cache 上存在,发生修改时需要写回内存并通知持有这个 cache line 的 CPU 失效,状态变为 E,没有变为 E 状态会一直等等
I : invalid
数据失效,在这个 cache line 上的读操作需要,把其它 CPU 上同一个 Cacheline 处于 M 或者 E 状态的苏局更新到内存,然后再从内存读取到当前 CPU 的 cache line 上,状态变为 S
对于写操作会把数据先按照读的流程更新到当前的 cpu chache line 上,然后在对这个 cache line 的数据进行写操作,再把数据写回内存并通知其它 CPU 上的 cache line 失效,状态变为 E
可以看出只有当 cache line 的状态属于 M 或者 E 时才不需要 touch 内存
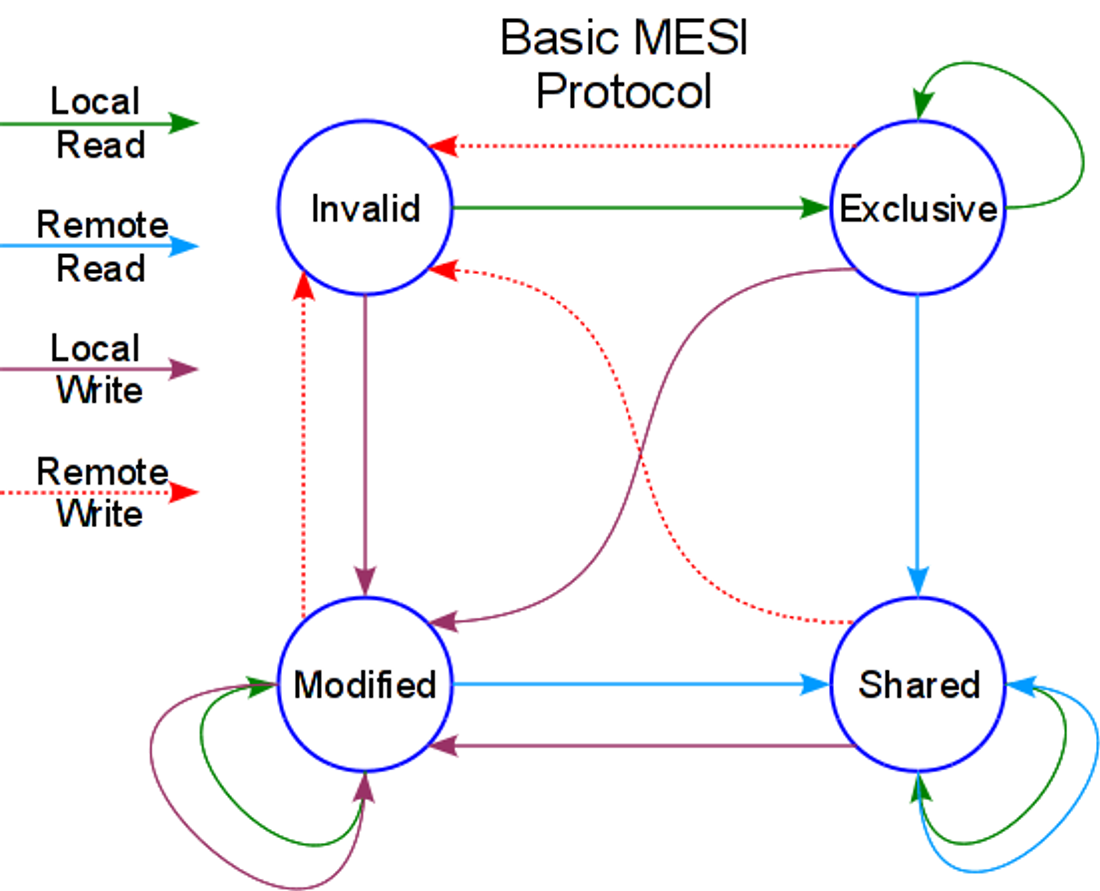
所以当有两个 CPU 同时对一个 cache line 进行读写的时候,cache line 的状态变化图

实际的状态变化可能会更复杂,因为在同时读写的时候,如果数据在总线里面可以直接获取,还有 M 状态变化到 I 的时候会先变成 S 状态如果此时有写操作才会变成 E 状态。
可以看到在一个 cache line 冲突的时候 每执行 N 次修改操作,当前的 cache line 会被别的 CPU 标记为 失效, 下次写入操作需要 touch 内存,同步其它的 cache line 后状态变为 E 开始在 L1 缓存里面继续执行 N 次。所以单个操作的时间估算: 理论上 和 大致相等。估算以后修改操作的性能可能会下降一倍左右,但是由于前面讲的会有冲突数据在数据总线上的情况,所以不需要访问内存,(少一次读操作但是要写回内存)所以理论上当两个 goroutine 分别在两个 CPU 上读写性能会降低一倍。
修改下前面的测试 case 把里面改为只有一个操作 总时间变为 420 ms 左右表明实际性能大概只降低了 1.2 到 1.3 倍左右 这是因为为了优化 MESI 中 I 状态写阻塞的情况,引入了 Store buffer 和 nvalidate Queue 来提升性能。
Store buffer
在写入 Invalid 状态的缓存时,CPU 会先发出 read-invalid(这样其它 CPU 的缓存行会写入更改并变成 Invalid 的状态),然后把要写入的内容先放在 Store buffer 上,等收到其它 CPU 或内存发送过来的缓存行,做合并后才真正完成写入操作。
这会导致虽然 CPU 以为某个修改写入缓存了,但其实还在 Store buffer 里。此时如果要读数据,则需要先扫描 Store buffer,此外,其它 CPU 在数据真正写入缓存之前是看不到这次写入的。
Invalidate Queue
当收到 Invalidate 申请时(如 Shared 状态收到 BusUpgr),CPU 会将申请记录到内部的Invalidate Queue,并立马返回/响应。缓存会尽快处理这些请求,但不保证“立马完成”。此时 CPU 可能以为缓存已经失效,但真的尝试读取时,缓存还没有置为 Invalid 状态,于是读到旧的数据。
根据这两个优化规则理论上我们跨两个 CPU cache line 也会被优化速度也应该很快,但实际性能慢了快 20 倍。这是因为 store buffer 和 Invalidate Queue 会带来一个代码执行顺序的问题,一般情况下为了保证执行顺序的正确性引入了内存屏障来保证执行顺序:插入 store barrier 会强制将 store buffer 的数据写到缓存中,这样保证数据写到了所有的缓存里;插入 read barrier 会保证 invalidate queue 的请求都已经被处理,这样其它 CPU 的修改都已经对当前 CPU可见。回到跨两个 cpu cache line 并发读写的 case,现在的时序图就会变成这样。
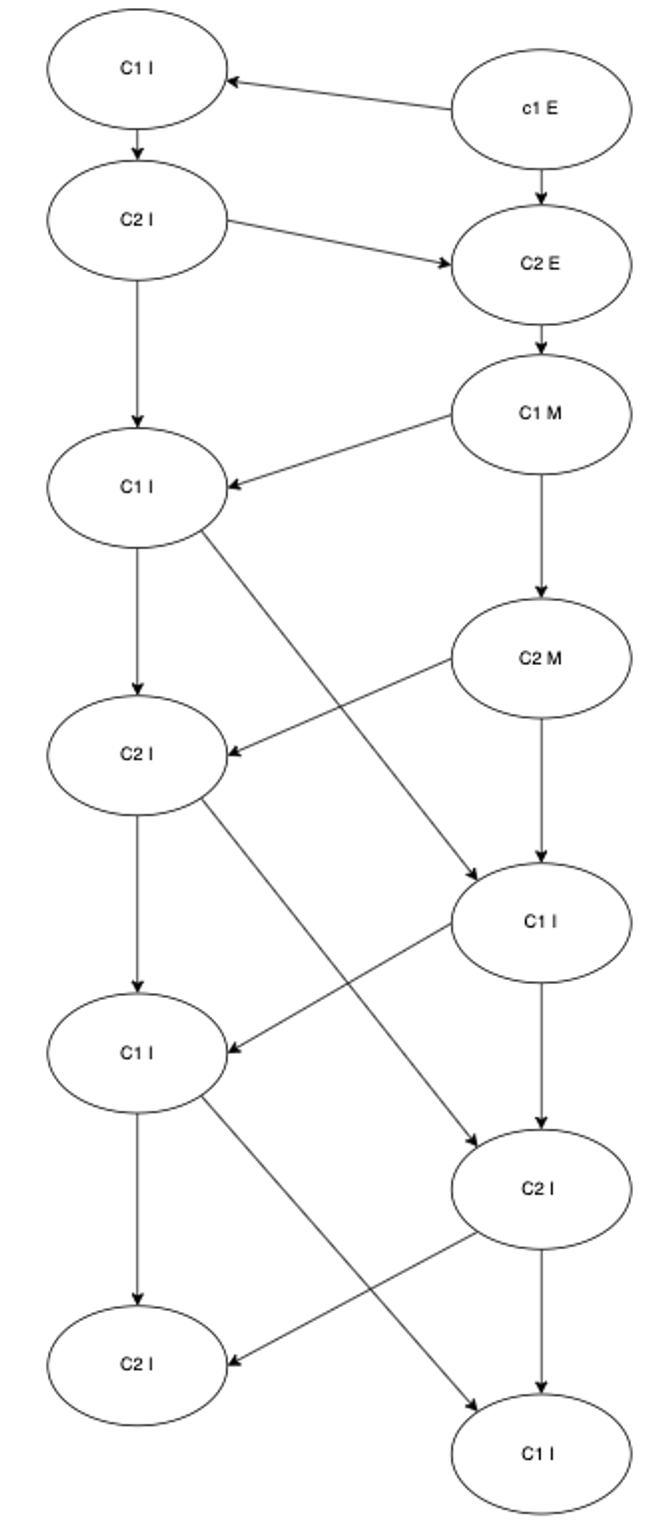
最终在迭代几次后每一次读写 C1 C2 状态都是 I 加上内存屏障的限制必须要 touch 一次内存,也就变成了所有的操作都访问内存了而 L1 和 内存的速度正好在20 倍左右。至于为什么同时访问多个 cpu cache line 比如 C1, C2, C3, C4 总的时间几乎不变是因为访问内存的操作可以合并,所以最终结果还是和 C1 C2 共耦类似
 Foreversmart
Foreversmart