Golang 调度器的设计和行为可以让多线程运行的程序更高效的运行, 因为 Golang 调度器对操作系统的熟悉运用 (mechanical sympathies) . 如果设计多线程程序的时候没有对 Golang 调度器有深刻的理解可能会导致性能更差.
(mechanical sympathies) : 硬件或机械理解能力
OS Scheduler
NUMA: 通过把 CPU 和临近的 RAM 当做一个 node,CPU 会优先访问距离近的 RAM。同时,CPU 直接有一个快速通道连接,所以 每个CPU 还是访问到所有的 RAM 位置(只是速度会有差异)。避免多 CPU 单一总线称为瓶颈.
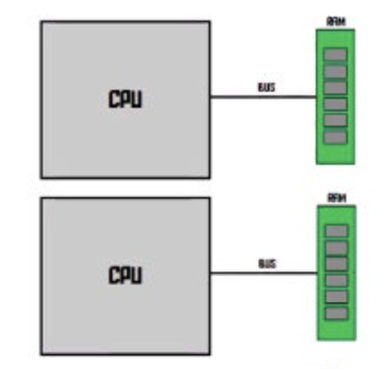
OS Scheduler 的设计需要考虑到包括不限于多处理器和多核,CPU caches 和 NUMA 等硬件知识才可以尽可能的高效的工作.
计算机程序是一系列的机器指令, 这些机器指令一个一个的被线性执行. 操作系统使用了线程的概念 Thread 来实现这个工作. 线程负责顺序的执行分配给它的指令直到没有指令为止.
每个程序都会创建一个进程, 每个进程都会有一个初始的线程. 线程可以在线程里面创建更多的线程, 每个线程都是独立的被操作系统调度执行, 线程的调度是在线程层面而不是进程的层面. 线程可以并发的执行(在一个核上通过时间片的方式)也可以并行的执行(不同的核同时执行). 线程需要维护一个状态保证代码的安全,本地,独立的执行.
OS Scheduler 会保证到有线程需要执行的时候不会让 core 处于空闲状态. 在调度的过程中对于所有可以执行的线程来说会产生一种他们都在同时执行的幻觉.线程在调度执行的过程中会让高优先级的线程先执行,同事对于低优先级的线程在执行时间上不会陷入饥饿. OS Scheduler 也需要通过快速和高效的策略尽可能的缩小在调度上的延迟.
Executing Instructions:
program counter(PC) 也被称为 instruction pointer (IP)是操作系统里面一个特殊的寄存器, 线程用来对下一个要执行指令进行追踪. 大多数处理器 PC 会指向下一条要执行的执行而不是当前执行的指令. 每条指令执行完会更新这个寄存器的值指向下一条指令,这样所有的指令都能顺序的一条一条的执行.
17096665
17096608
Thread States:
Waiting 表示线程处于停止和等待的状态, 可能是因为等待硬件设备(disk, network) 操作系统(system cal) 或者同步调用(synchronization calls 如 atomic, mutexes). 因为处于 Waiting 带来的延迟是造成系统性能低下的主要原因.
Runnable: 表示线程可以执行但是需要等待分配到 cpu 核上去执行
Executing 线程正在 CPU 核上执行
线程的工作类型:
CPU-Bound: 基本不会处于 Waiting 的状态, 处理的任务就是不停的进行计算,比如计算 Pi 值
IO-Bound: 处理的任务会让线程进入 Waiting 的状态, 有可能是通过网络请求资源或者对系统进行系统调用. 比如读写数据库的线程就是 IO-Bound, 同步事件(如锁和原子操作)都是这个类型.
上下文切换(context switch)
Linux, Mac, Windows 操作系统的线程调度都是抢占式的(preemptive scheduler). 意味着调度器无法预测线程在什么时候会被运行, 在加上线程的优先级和事件就更加难以进行决策.也意味着多个线程上的代码执行顺序无法保证需要增加同步操作或者精心的编排调度.
在一个 CPU Core 上线程交换的物理行为就是上下文切换. 从一个 run queue 选择的线程替代正在执行的线程. 新的线程变为 Executing 状态, 老的线程变为 Runnable 状态(如果还可以再次运行) 或者 Waiting 状态 (因为 IO-Bound 的行为发生的切换)
上下文切换会消耗大量的性能,因为它会将 CPU 上线程用到的寄存器保存到内存中, 然后再把需要加载的线程从内存加载到寄存器里(是否可以通过 CPU cache 预载加速切换速度?) 通常需要花 ~1000 and ~1500 nanoseconds 左右进行切换 (https://eli.thegreenplace.net/2018/measuring-context-switching-and-memory-overheads-for-linux-threads/ 进行测量) , 而一般的硬件情况下单核大概可以 一纳秒执行12个指令左右, 所以上下文切换会带来12k 到 18k 左右的指令执行延迟.
对于 IO 密集的任务,上下文切换会带来优势,一个线程进入 waiting 的时候调度另外一个 Runnable 的线程执行, 保证 CPU 核心一直在处理任务 (Don’t allow a core to go idle if there is work). 这是通常调度带来的最大意义.
对于 CPU 计算密集的任务, 上下文切换会带来性能上的灾难. 因为线程本身有很多的计算任务, 额外的上下文切换带来了额外的性能负担, 且没有带来任何意义上的加速.
早期的结构中 https://lwn.net/Articles/404993/ scheduler period 调度周期是指在这个时间周期内会遍历所有的 Runnable 进行执行, 线程约多同等的调度周期内分配到的单个线程执行的时间就越短, 当短于某个程度的时候上下文切换带来的性能损失比重越大. 而如果增加调度周期的长度则会造成饥饿现象. 在写具体的代码的过程中需要对 CPU 核数和线程个数进行一个平衡, 线程池是一个比较好解决方案. 不同的场景下单个 CPU 上达到最佳性能的线程个数是不同的. 比如访问数据库的应用通常是3
Cacheline
通过 Cacheline 可以加速处理器访问数据的速度, 访问数据的速度之间影响到程序的性能
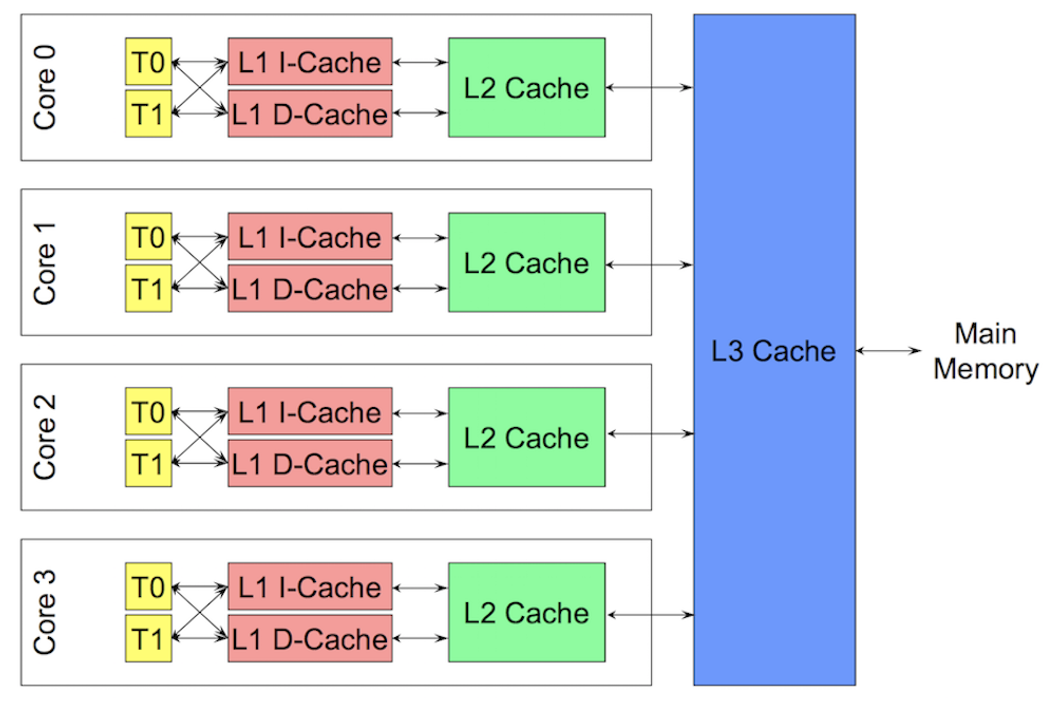
数据通过 cache 在主存 Main memory 和处理器上进行交换, 每个核都会拷贝一份自己需要数据的 Cache line. 多线程在对内存的修改可能会极大的影响性能.当两个线程修改同一个数据或者相邻的数据的时候会产生 False Sharing 问题. 当一个线程修改它的 cache line 的时候其它 core 上相同的 cache line 就会失效然后在需要的时候重新从主存加载 (~100 to ~300 clock cycles). 当多核和多线程的时候会产生很大的性能影响.
GO Scheduler
当 GO 程序启动的时候会给每一个宿主机上的虚拟核分配一个逻辑的处理器 Logical Processor (P). 如果处理器在每个物理核上带有硬件线程 (Hyper-Threading), 每个硬件线程也会被看做是一个虚拟核.

图上有4个核而 i7 处理器带有 Hyper-Threading 超线程,所以一共有8个虚拟核. 可以通过 Golang 代码查看宿主机具体的虚拟核数.
// NumCPU returns the number of logical
// CPUs usable by the current process.
runtime.NumCPU() // 8
Go
每一个逻辑处理器 P 会分配一个操作系统线程 M (Machine), 这些线程仍然被操作系统管理并且系统负责把线程放在 CPU 核上执行. 所以 GO 程序已启动就会被分配 8 个可用的线程来执行任务, 每一个线程被单独地分配给一个 P.
每一个 Golang 程序都会有一个初始化的 Goroutine (G),是 golang 程序的执行路径. Gorutine 本质上 Coroutine 因为在 Golang 里面所以把 C 换成了 G. Goroutine 是应用程序级别的线程和 OS 线程有很多相似的地方, OS 线程在 CPU 核上做上下文切换, 而 Goroutine 在线程 M 上做上下文切换.
run queues:
Global Run Queue (GRQ) 还没有分配给 P 的 Goroutine 的的队列
Local Run Queue (LRQ) 每一个 P 都有一个 LRQ 用来管理分配给 P 上下文执行的 Goroutine, LRQ 上的 Goroutines 轮流的在 P 的分配的线程 M 上切换执行.
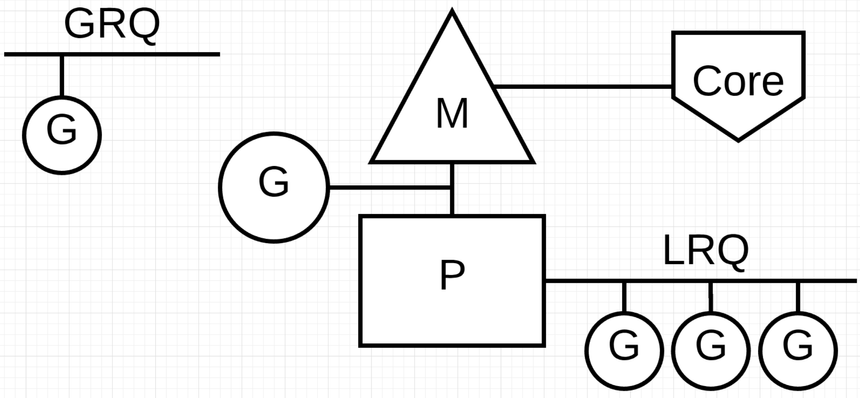
Cooperating Scheduler 协作调度器
Go scheduler 是 Go 程序 runtime 的一部分, Go 的 runtime 编译到应用代码里面. 所以 Golang 的调度器运行在用户空间而不是内核空间. Go scheduler 目前的实现不是抢占是调度器(preemptive scheduler) 而是协作调度器 (cooperating scheduler), 协作调度器需要定义好发生在代码安全点(safe points in the code)上的用户空间事件来做调度决策.
但是 Golang 调度器会让开发者觉得这还是一个抢占式调度器, 因为我们无法预测调度器接下来会做什么, 调度的决策控制在 Go 运行时(runtime) 里面而不是在开发者手里.
Goroutine States: 和线程1一样有3个优先级高的状态
Waiting: 表示协程处于停止和等待的状态, 可能是因为等待硬件设备(disk, network) 操作系统(system cal) 或者同步调用(synchronization calls 如 atomic, mutexes). 因为处于 Waiting 带来的延迟是造成系统性能低下的主要原因.
Runnable: 表示协程需要获得时间在 M 上执行指令,如果 Runnable 的协程很多, 等待运行的时间就越长, 也会造成性能的下降.
Executing: 表示协程正在分配的 M 上执行
Context Switching
Go scheduler 需要定义好发生在代码安全点(safe points in the code)上的用户空间事件来切换上下文. 这些安全点和用户事件在函数调用里面. 函数调用对于调度器的监控至关重要,如果代码里面充满了循环而没有函数调用, 调度器 (scheduler) 和 垃圾回收 (garbage collection)会产生延迟. 在 golang 1.14 里面增加了抢占式调度  Issue #24543 https://go.dev/doc/go1.14 在这前的这之前如果 for{} 会阻塞调度器和垃圾回收. 但是只有 unix 系统支持
Issue #24543 https://go.dev/doc/go1.14 在这前的这之前如果 for{} 会阻塞调度器和垃圾回收. 但是只有 unix 系统支持
下面4类事件可以允许 go 调度器做调度决策,并不是一定做出调度,只是调度器获得了调度的机会.
go 关键字 : 用来创建协程,一但一个 goroutine 创建出来,调度器获得了重新调度的机会
Garbage collection 垃圾回收:
因为 GC 运行在自己的一组协程上, 这些协程需要获得在 M 上运行的时间, 这导致 GC 产生了大量调度的混乱. 同时 Golang 的调度器非常的智能, 一个聪明的决策是在 GC 的过程中把使用堆和不使用堆的协程进行上下文切换. 当 GC 运行的过程中, 可能会做很多调度策略.
System calls 系统调用
系统调用会导致 goroutine 阻塞 M , 有时调度器能够把这个协程从这个 M 上切走, 然后给这个 M 切换一个新的协程. 然后有时也需要一个新的 M 用来执行 P 队里里的协程.
同步和编排操作(channel)
atomic, mutex, channel 会导致协程阻塞, 调度器会切换一个新的 G 运行, 一但阻塞完成再加入到 run queue 里, 最终被执行.
Asynchronous System Calls 异步系统调用
当操作系统可以异步地调用系统调用时可以提高性能. 比如 network poller https://go.dev/src/runtime/netpoll.go . MacOs 使用 kqueue, Linux 使用 epoll, Windows 使用 iocp 实现. 基于网络的系统调用现在可以被很多操作系统异步化. 通过使用 network poller 调度器可以让 goroutine 在调用网络系统调用的时候阻塞 M. 这可以让这个 M 去执行 P 本地 run queue 里面的其它 Goroutine, 而不需要重新创建一个 M. 这样可以降低操作系统调度的负载.
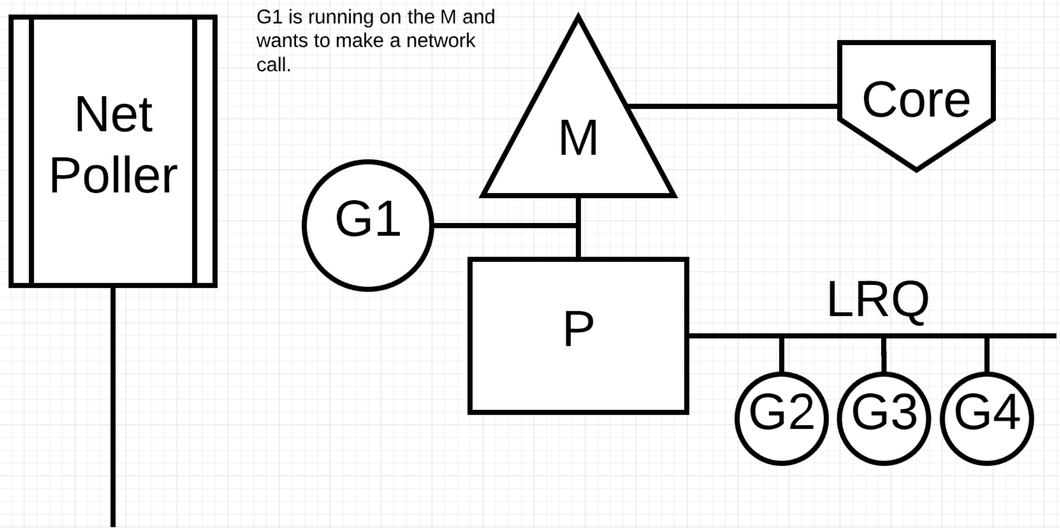
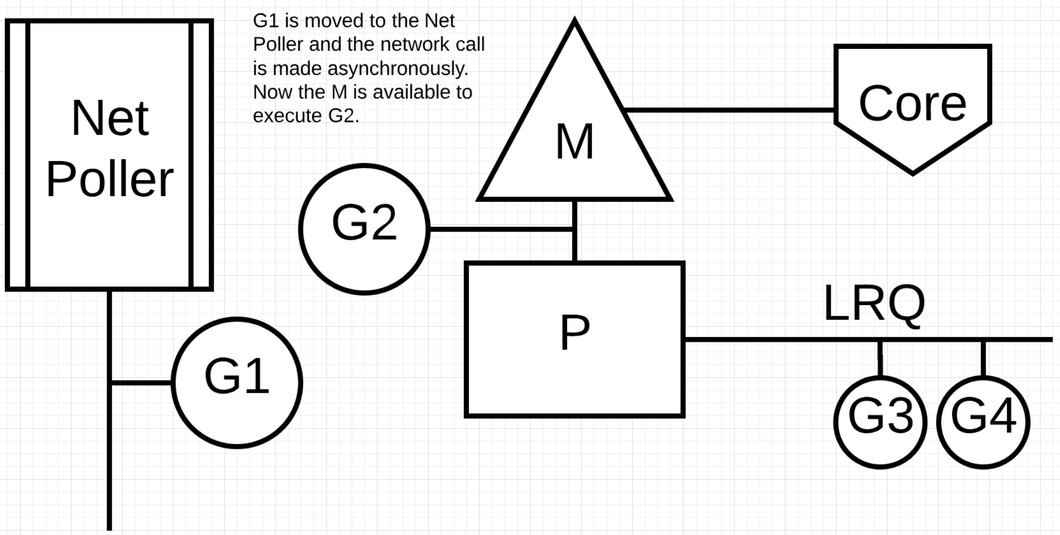
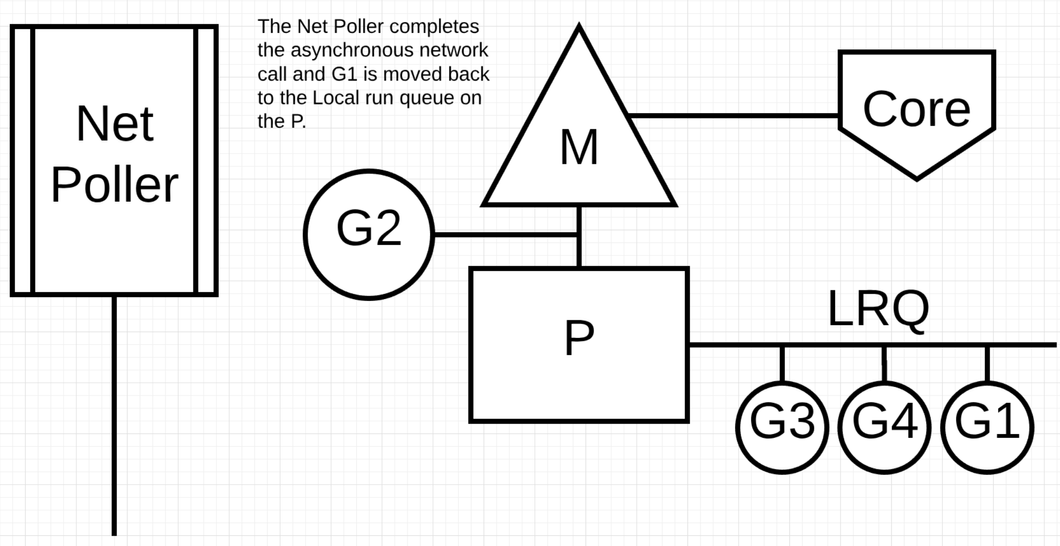
当 G1 发生网络调用时,把 G1 移到 Net Poller 上执行 P 切换到下一个 G2 执行. 执行完 G1 的网络请求后将 G1 移回 P 的 LRQ 中. Net Poller 里面有一个 OS 线程在高效的处理事件循环.
Synchronous System Calls 同步系统调用
比如基于文件的操作, CGO 都是同步的调用会阻塞 M. 注意: 在 windows 有技术可以实现异步的文件操作调用.
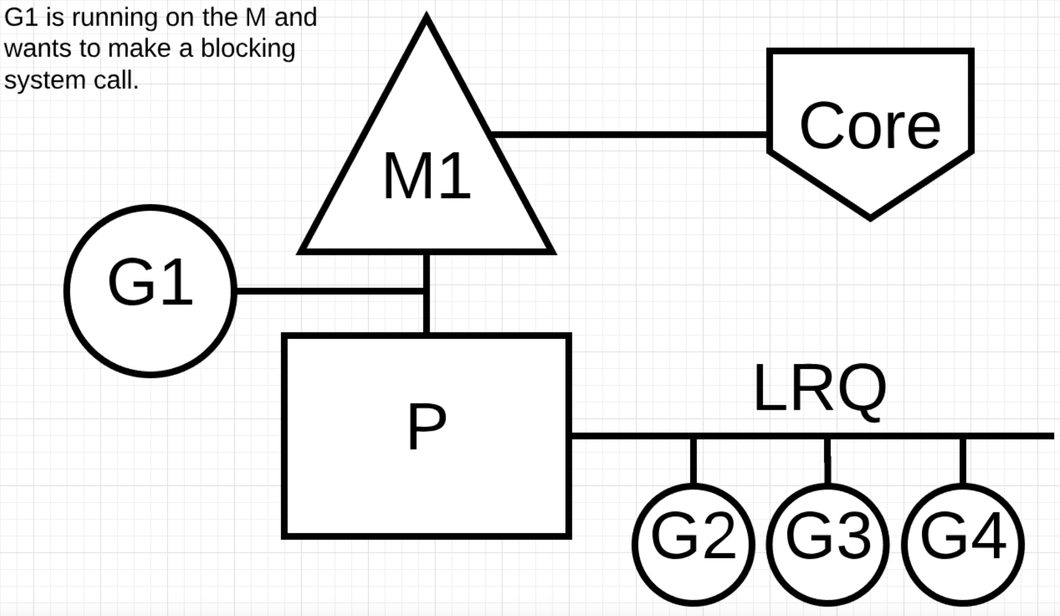
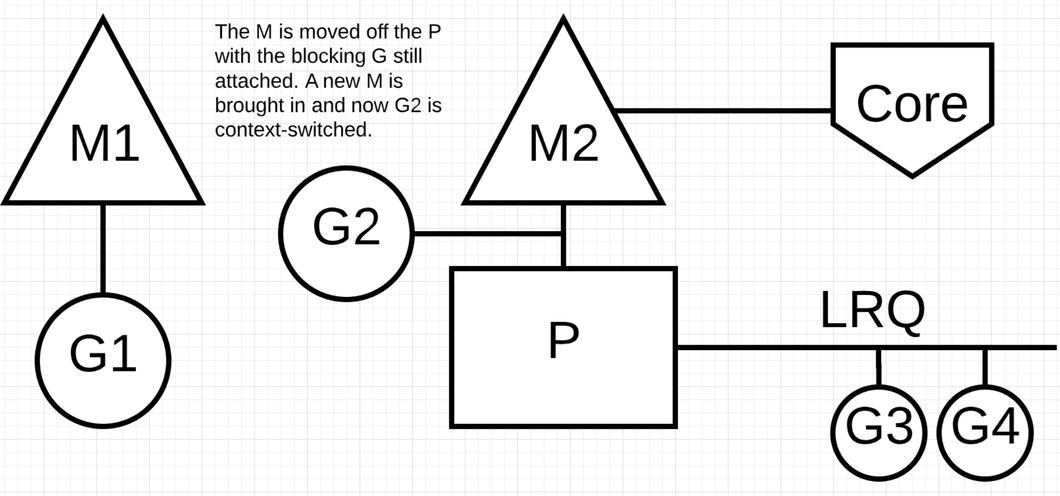
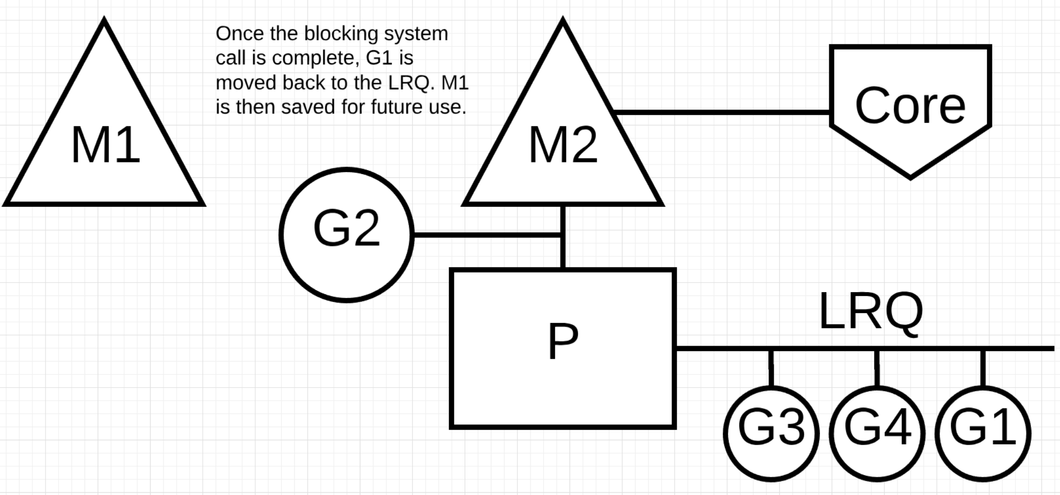
当 G1 发生同步调用时 G1 会阻塞 M1, 此时 M1 和 P 解绑. P 会获取一个新的线程 M2 (如果没有闲置的线程需要新建). 当 G1 完成操作重新加入到 P 的 LRQ 里面, M1 作为一个限制的线程给别的 P 在这种场景使用.
Work Stealing 获取协程
窃取协程调度可以使调度更加的高效, 如果一个 M 已经从 CPU 上切换走了, 那意味 P 上就执行不了任何任务了, 直到 M 重新切换到 CPU 上. 协程窃取可以帮助平衡所有 P 上的协程让它们更好的分布和高效的执行.
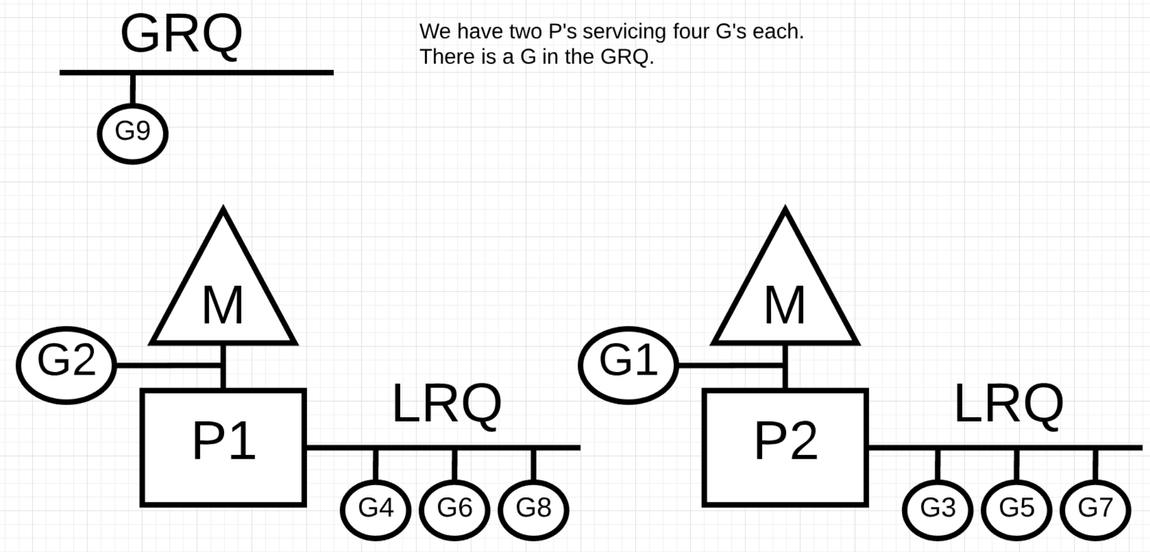
开始有两个 P 分别有 4 个协程
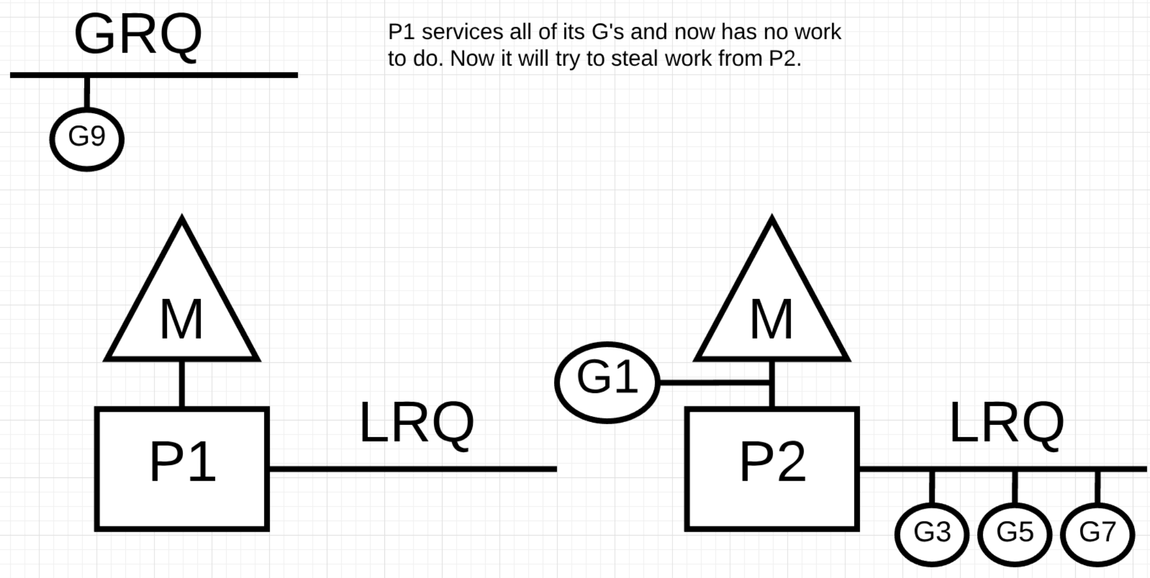
P1 运行的比 P2 快, P1 本地的 LRQ 没有 runnable 的 G 可用, 这个时候 M 会执行随机逻辑 Spinning threads https://golang.org/src/runtime/proc.go 大致的逻辑如下
runtime.schedule() {
// only 1/61 of the time, check the global runnable queue for a G.
// if not found, check the local queue.
// if not found,
// try to steal from other Ps.
// if not, check the global runnable queue.
// if not found, poll network.
}
Go
在从其它 P 获取协程的时候会随机选择一个 P 获取一半的 LRQ 的 G 到自己的 LRQ 里
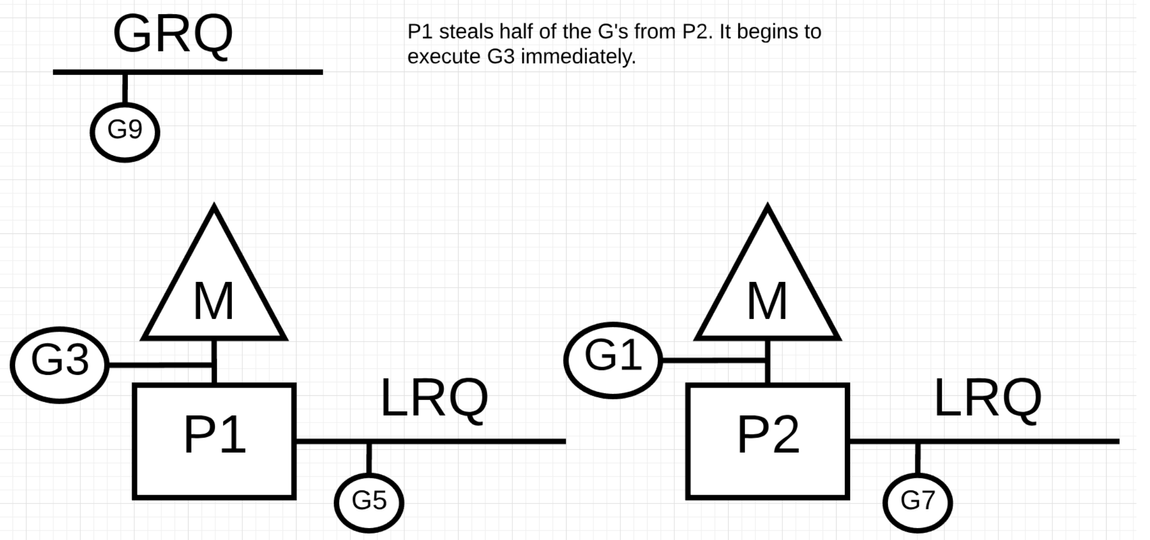
P1 获取 P2 LRQ 的 G3 和 G5 执行
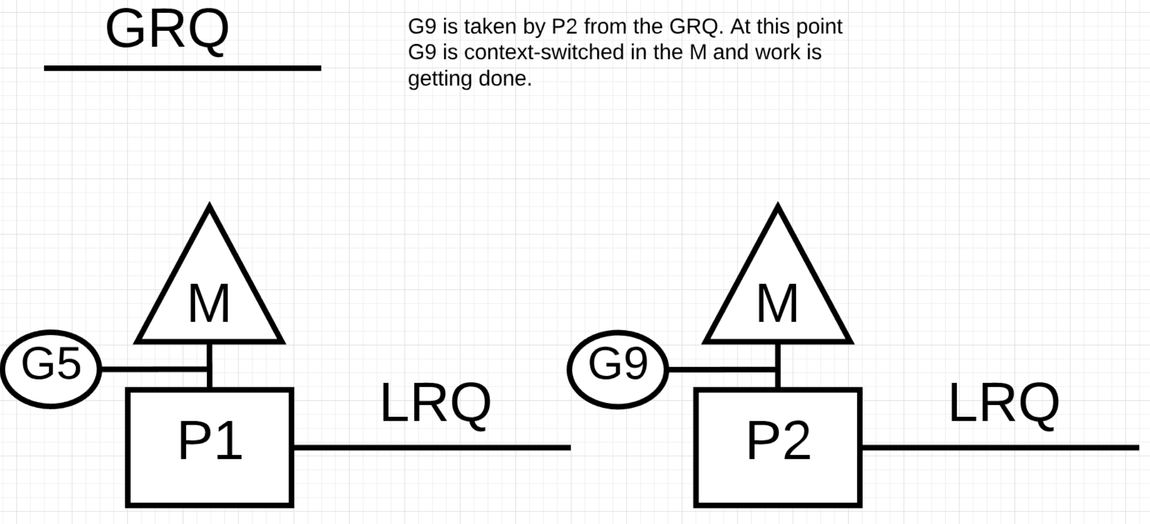
P2 执行完了 LRQ ,且其它的 P 没有只能从全局队列中获取一个 G 执行.
Golang 通过内置在 M 里面 Spinning threads , 避免线程在调度的时候发生大量的竞争和加锁去锁的过程. 当一个 M在下面情况的时候会进入 Spinning 状态:
当分配了 P 的 M 在寻找可运行的 G 的时候
没有分配 P 的 M 在寻找可以运行的 P
较线程和协程的运行:
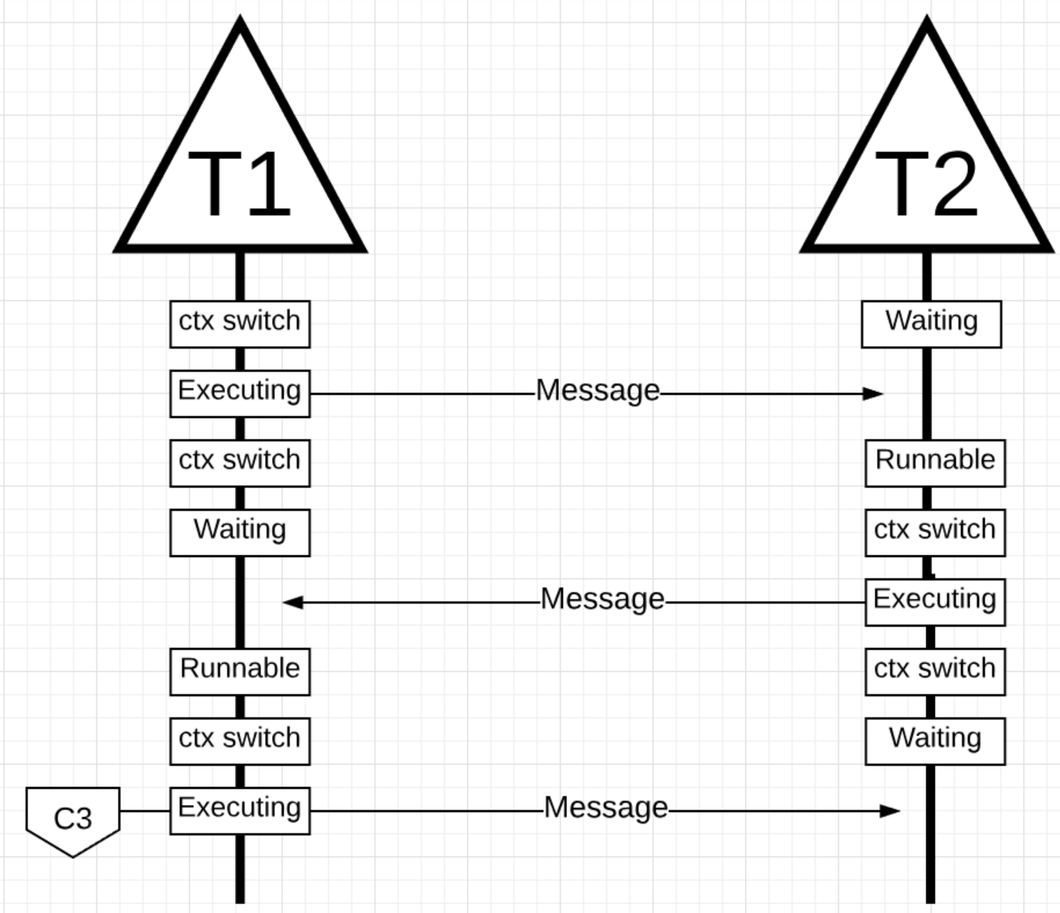
线程切换的时候会消耗大量的 CPU 时间, 线程在上下文切换的时候可能会在不同 CPU core 上, 会导致 cpu cache 失效.
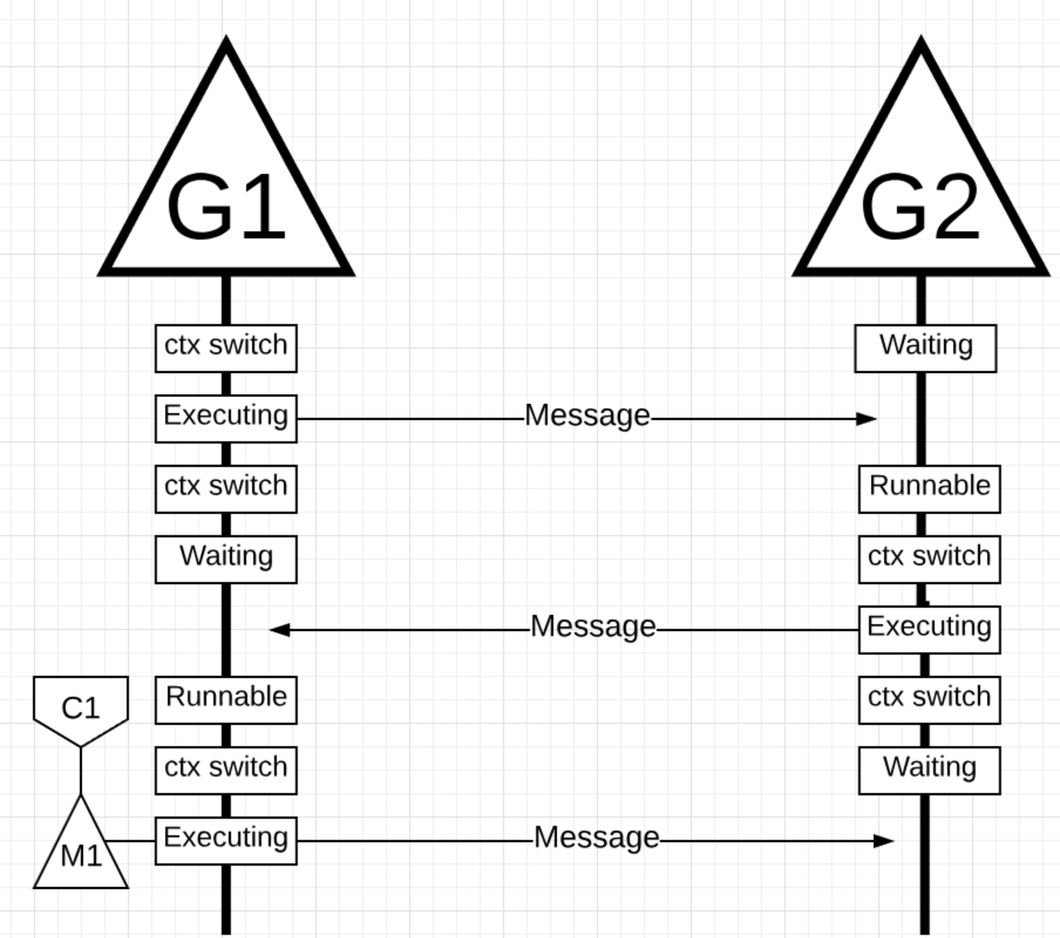
协程在做上下文切换, 对应的操作系统线程没有切换一直在执行, 并且调度器可以更好的利用 CPU cache 和 NUMA 进行调度. 在系统层面把 IO/Blocking work 变成 CPU-bound work.
 Foreversmart
Foreversmart